TOON: cuando los datos aprenden a hablar en el idioma de la IA
Hace unos días me crucé con algo llamado TOON. No era una nueva librería, ni un modelo, ni una API. Era un formato de datos. Uno más, pensé. Pero cuando lo miré más de cerca, entendí que había algo distinto.
Durante años trabajamos con JSON sin cuestionarlo. Fue el lenguaje invisible que sostuvo casi todo lo que hacemos: APIs, configuraciones, integraciones. Pero con la llegada de los modelos de lenguaje grandes (LLMs), algo cambió. Cada coma, cada llave y cada comilla ahora tienen un costo. Literalmente. Cada carácter se convierte en un token, y los tokens cuestan dinero y espacio dentro del contexto del modelo.
Cuando los formatos vuelven a importar
Hasta hace poco, elegir entre JSON, YAML o CSV era una cuestión de estilo. Ahora es una cuestión de eficiencia. Los modelos de lenguaje no procesan estructuras de datos, procesan texto. Y cuando todo se mide en tokens, la sintaxis deja de ser un detalle estético y pasa a ser un factor técnico importante.
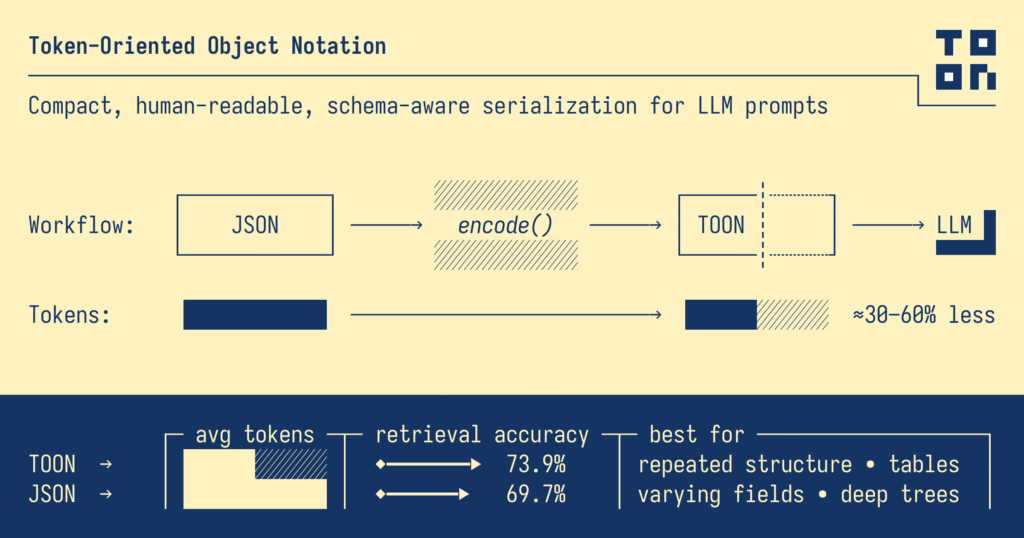
Ahí aparece TOON, abreviatura de Token-Oriented Object Notation. Su propósito es reducir el ruido del formato, mantener la estructura y permitir que los modelos lean más con menos. En otras palabras, está diseñado para hablarle mejor a la inteligencia artificial.
Qué lo hace distinto
La idea de TOON es simple: eliminar la redundancia. En lugar de repetir nombres de campos y abrir y cerrar llaves sin parar, usa una combinación de indentación y formato tabular que resulta más compacta y natural tanto para los humanos como para los modelos.
Por ejemplo:
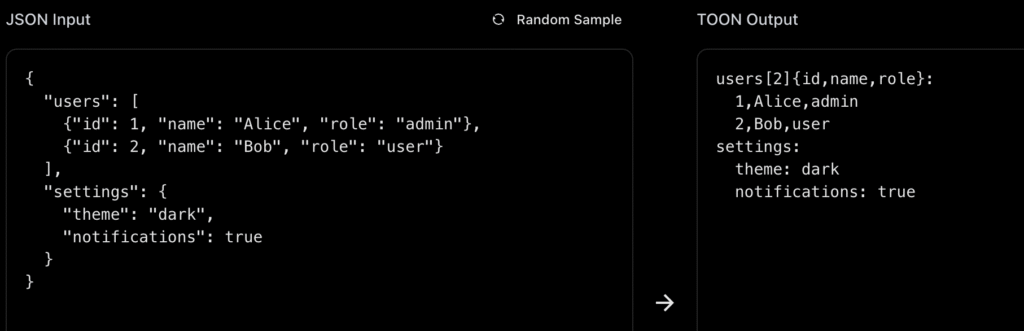
{
"users": [
{ "id": 1, "name": "Alice", "role": "admin" },
{ "id": 2, "name": "Bob", "role": "user" }
]
}
en TOON se escribe así:
users[^2]{id,name,role}:
1,Alice,admin
2,Bob,user
El resultado es el mismo, pero con la mitad de tokens y una estructura más limpia. Se parece más a una tabla que a un árbol. No hay ruido visual, no hay repeticiones innecesarias. Solo los datos.
Qué se gana al usarlo
El primer beneficio es evidente: ahorro de tokens, que puede ir del 30% al 60% según el tipo de datos. Eso se traduce en prompts más largos, respuestas más ricas y costos más bajos al trabajar con APIs de modelos.
El segundo es claridad estructural. TOON facilita que los modelos comprendan mejor la relación entre los campos, porque presenta los datos de una manera más consistente y explícita. Y el tercero, más sutil, es fluidez: cuando te acostumbrás al formato, leer TOON se siente más natural que leer JSON.
Probarlo en minutos
Ya existe un paquete en npm:
npm install @toon-format/toon
Y si querés probarlo sin instalar nada, podés ir a jsontoon.com y pegar cualquier JSON.
La herramienta genera la versión en TOON y muestra la diferencia de tokens. Es una de esas pruebas simples que hacen evidente por qué este formato tiene sentido.
Impresión personal
Lo que más me llamó la atención de TOON no fue la sintaxis, sino la intención detrás. No se trata solo de ahorrar tokens, sino de adaptar el lenguaje de los datos a un nuevo tipo de lector. Así como en su momento aprendimos a escribir código que los humanos pudieran mantener, ahora estamos empezando a pensar en cómo escribir información que las máquinas comprendan mejor.
Esa idea —más pragmática que revolucionaria— refleja algo que está ocurriendo en silencio: la programación ya no se trata solo de dar instrucciones, sino también de comunicarse con sistemas que interpretan el lenguaje de formas cada vez más cercanas a las nuestras.